
Understanding Types of Cluster Computing | Rockborne

Cluster Computing
The computing limitations of individual server hardware i.e. CPUs and RAM called for a solution to effectively process the huge amounts of data produced in recent years. Cluster computing enables calculations and storage to be distributed across multiple computers. Specifically, Hadoop and more recently Spark have been the most popular software tools for cluster computing in big data, providing a means to store data across different computers or ‘nodes’ and divide a task effectively across those different machines.
About Hadoop
Hadoop is an ecosystem combining MapReduce, HDFS and YARN.
- When using Hadoop, data is stored across different nodes using HDFS (Hadoop Distributed File System), providing a fault-tolerant storage by replicating data across 3 different nodes.
- Next, data is extracted from different nodes (i.e. different physical databases) and queries computed at each node and the output sent to a master node. This is the MapReduce stage.
- YARN (Yet Another Resource Negotiator), as the name suggests, manages resources and processes Job requests. It is essential for when multiple jobs are run on Hadoop simultaneously(1).
Ultimately, Hadoop allows for faster processing and analysis of data, while being highly scalable and flexible (2). It is estimated that compared to other data management technologies, the cost of a Hadoop management system, including hardware software and other expenses comes to around one-fifth to one-twentieth the cost (3). At the core of Apache Hadoop is the MapReduce programming model that processes data in batches.
About MapReduce
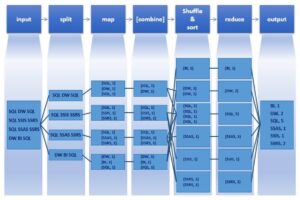 Figure 1. Schematic of MapReduce using word count as an example (4)
Figure 1. Schematic of MapReduce using word count as an example (4)
The MapReduce function can be used to apply operations on a set of data whereby the problem can be broken down into smaller, independent ‘sub-problems’ which are solved and then aggregated to produce an answer to the bigger problem. An example of how MapReduce works is given in Figure 1. Here, you want to calculate the number each word appears in a large dataset.
- The mapping stage involves creating key-value pairs with the key being the word and value being the frequency of that word (mapping phase). Sometimes a combine phase is added whereby key/value pairs with the same key are combined i.e. pairs (SQL,1) and (SQL,1) are shrunk to make (SQL,2).
- Next, during the shuffle/sort stage, data from all mappers are grouped and ordered by the key. This saves time for the reducer, helping it easily distinguish when a new reduce task should start.
- Finally, during the reduce stage the values for each key are added up and combined to a single output file.
Where Apache Spark comes into play
While Hadoop performs operations on the computer disk drive, Apache Spark loads its data onto RAM, enabling up to 100x faster processing of data for smaller workloads, although it is typically 3x faster for larger workloads (5).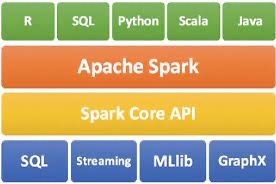 Figure 2. Apache Spark EcosystemThe spark ecosystem consists of 5 primary modules: Spark core, Spark SQL, Spark Streaming and Structured Streaming, Machine Learning Library and GraphX (5). Spark core is the underlying execution engine that uses RDDs (Resilient Distributed Datasets) to process and store data and are a read-only collection of records. They consist of multiple datasets that are partitioned across multiple servers, so that they can be computed on different nodes of the cluster (6).
Figure 2. Apache Spark EcosystemThe spark ecosystem consists of 5 primary modules: Spark core, Spark SQL, Spark Streaming and Structured Streaming, Machine Learning Library and GraphX (5). Spark core is the underlying execution engine that uses RDDs (Resilient Distributed Datasets) to process and store data and are a read-only collection of records. They consist of multiple datasets that are partitioned across multiple servers, so that they can be computed on different nodes of the cluster (6).
Hadoop vs Spark
Because of the way Spark operates, it is faster, can process data in real-time (useful for applications such as targeted advertising) and is much preferred for machine learning due to the in-built machine learning library.
However, Hadoop, although an older technology still has advantages such as being cheaper (due to relying on disk storage not RAM), is highly scalable via the HDFS and is more secure (5).
Bibliography
- Simplilearn. Youtube. [Online] [Cited: Aug 5, 2022.] https://www.youtube.com/watch?v=aReuLtY0YMI&t=214s&ab_channel=Simplilearn.
- [Online] 07 2022, 26. https://www.informationweek.com/software/how-hadoop-cuts-big-data-costs.
- [Online] [Cited: 07 26, 2022.] https://www.informationweek.com/software/how-hadoop-cuts-big-data-costs.
- Sindol, Dattatrey. Big Data Basics – Part 5 – Introduction to MapReduce . mssqltips. [Online] [Cited: Aug 5, 2022.] https://www.mssqltips.com/sqlservertip/3222/big-data-basics-part-5-introduction-to-mapreduce/.
- Education, IBM Cloud. Hadoop vs. Spark: What’s the Difference? . ibm. [Online] [Cited: Aug 5, 2022.] https://www.ibm.com/cloud/blog/hadoop-vs-spark.
Share


