26 Oct 23
Sampling Methods to Combat Imbalanced Data in Machine Learning

Hermione Lamb
Imbalanced classes are a common challenge in machine learning where one class in a dataset has significantly fewer instances than the other.
This can lead to models that are biased towards the majority class, resulting in poor performance on the minority class. In this blog post, we’ll explore several techniques to address this issue, including random under and over-sampling, Tomek Links, Near Miss, and SMOTE.
When is resampling needed?
Resampling techniques are employed when dealing with imbalanced classes. This imbalance can lead to models that are overly influenced by the majority class, potentially causing critical information in the minority class to be overlooked. By resampling the data, we aim to balance the representation of each class, enabling the model to make more accurate predictions.
Imbalanced data is a prevalent issue in numerous fields, spanning from medical diagnostics to fraud detection and sentiment analysis. For instance, in medical research, rare diseases often result in datasets where positive cases are notably outnumbered by negatives. Similarly, in financial institutions, instances of fraud are relatively scarce compared to legitimate transactions.
Under-Sampling Techniques
Random Under-Sampling
Random under-sampling involves randomly removing instances from the majority class to balance the dataset. While this method can be effective, it runs the risk of removing potentially valuable information.

Tomek Links
Tomek links are pairs of instances from different classes that are very close to each other. Removing the majority class instance of such a pair can help create a clearer margin of separation between the classes. This technique is especially useful when the data is spread out and Tomek links can be easily identified.
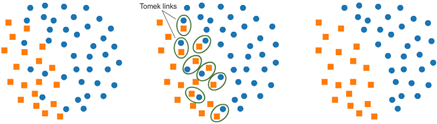
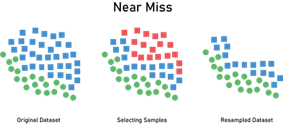
Near Miss
Near Miss is a collection of three under-sampling techniques which use the distances between the majority and minority class points to perform resampling. The first method selects the majority class points that are closest to the 3 closest minority class points, where the second method selects those that are closest to the 3 minority class points that are furthest away. The third method selects a given number of majority class points that are closest to each of the minority class points. Shown below is the first method, and this helps to retain instances that are most similar to the minority class, potentially preserving critical information.
Over-Sampling Techniques
Random Over-Sampling
Random over-sampling involves duplicating instances from the minority class. This can be an effective way to augment the dataset and provide the model with more information on the minority class. However, it may also lead to overfitting, so it’s important to be cautious.

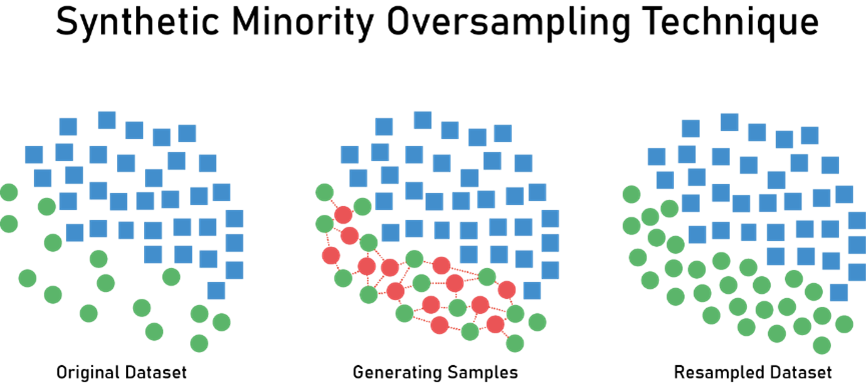
SMOTE (Synthetic Minority Over-sampling Technique)
SMOTE works by creating synthetic samples in the feature space. It randomly selects a point from the minority class and its k-nearest neighbours, then generates a random number between 0 and 1 to combine them and create a new instance. SMOTE can be highly effective in balancing classes while also avoiding overfitting.
Over and Under-Sampling Pros and Cons
Over Sampling
Pros
- Augments the dataset, providing more information to the model.
- Reduces the risk of underfitting.
- Can improve model performance on the minority class.
- Can be particularly effective when the available data is limited.
Cons
- May lead to overfitting, especially if not carefully implemented.
- Can result in a larger and potentially slower-to-train model.
- May increase the computational resources required for training.
- Can introduce noise if not balanced with appropriate techniques.
Under Sampling
Pros
- Reduces the computational resources required to train the model.
- Can help mitigate the risk of overfitting.
- Can lead to faster training times and more efficient models.
- May simplify the decision boundary, potentially resulting in better generalization.
Cons
- May remove potentially valuable information from the majority class.
- Risk of underfitting if not applied carefully.
- Can lead to loss of diversity within the dataset.
- May not be suitable for cases with very limited data in the majority class.
It’s important to carefully consider these pros and cons when deciding between over and under-sampling techniques, as the choice can significantly impact the performance and behavior of the resulting machine learning model.
Choosing the Right Technique
Choosing the most suitable technique depends on the dataset and problem at hand. It’s often beneficial to experiment with different approaches and evaluate their performance using metrics that are sensitive to imbalanced classes, such as precision, recall, and F1-score.
However, some tips can be given as a rough guide on how to choose over or under-sampling. Firstly, it is advised to oversample the data unless you have a reason not to, i.e. use oversampling as a default. Reasons to use undersampling include cases where very large amounts of data are being processed and where oversampling leads to overfitting of the model.
Conclusion
Dealing with imbalanced classes is a critical aspect of building robust machine learning models. By employing techniques like random under and over-sampling, Tomek links, SMOTE, and near miss, practitioners can create more balanced datasets and ultimately, more effective models.
However, it’s important to note that there is no one-size-fits-all solution, and careful consideration of the specific problem and dataset is essential. With the right approach, imbalanced classes can be successfully handled, leading to models that are both accurate and reliable.
Related posts
Life at Rockborne20 Jun 25
Federated Learning: The Future of Collaborative AI in Action
Federated Learning: The Future of Collaborative AI in Action The way we build, deploy, and govern AI is evolving, and so are the expectations placed on organisations to do this...
09 Sep 24
Tips to Succeed in Data Without a STEM Degree
By Farah Hussain I graduated in Politics with French, ventured into retail management, dabbled in entrepreneurship, a mini course in SQL and now… I am a Data Consultant at Rockborne....
Farah Hussain
15 Apr 24
Game Development at Rockborne: How is Python Used?
Just how is Python used in game development? In this blog post, we see the Rockborne consultants put their theory into practice. As the final project in their Python Basics...
